Có bao giờ mọi người thắc mắc Data Engineer đi phỏng vấn sẽ gặp những dạng câu hỏi như thế nào không? Câu chuyện hôm nay tui muốn chia sẻ là về một câu hỏi khá cơ bản mà nhà tuyển dụng thường đặt ra cho Data Engineer:
“Công ty đang có khoảng 100TB Data đang nằm trong Hadoop HDFS, lưu trữ ở định dạng text file, tăng dần theo thời gian. Do nhu cầu phát triển của công ty mà họ thành lập một team Data, bao gồm Data Engineer, Data Analyst và Data Scienitst. Với cương vị là Data Engineer đầu tiên của công ty, tui sẽ thiết kế hệ thống như thế nào để người dùng có thể xử lý và làm việc trên 100TB Data có sẵn. Ngoài ra còn xem xét trong tương lai, công ty sẽ chuyển toàn bộ hệ thống lên dịch vụ Cloud như AWS, Azure và Google."
Vậy, tui đã giải quyết như thế nào?
Để xử lý số lượng data có thể coi là “lớn” đó, tui đề xuất để sử dụng Apache Spark. Apache Spark là một Distributed Cluster Computing Framework (dịch ra là hệ thống xử lý phân tán), hỗ trợ cho việc xử lý dữ liệu lớn. Cách thức hoạt động của Spark có thể xem hình bên dưới
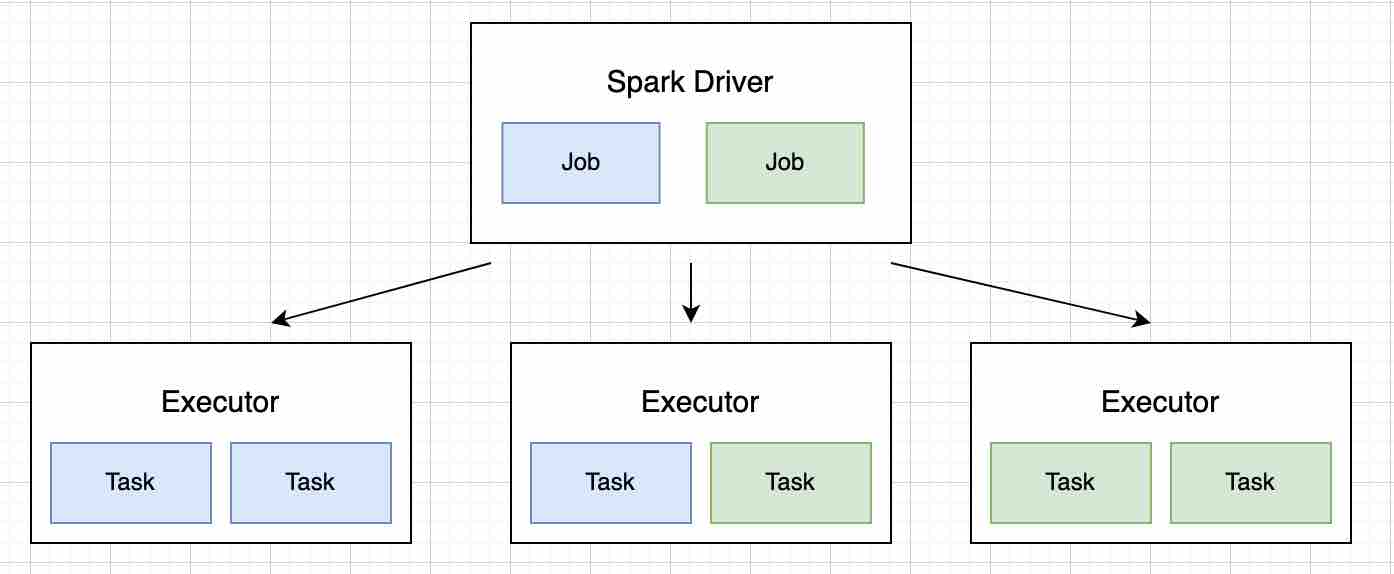
Tui ví dụ một bài toán nhỏ sau để mọi người dễ hình dung cách hoạt động của Spark.
Đọc khoảng 1TB data và tách column (cột) “date” thành 3 columns nhỏ hơn “year, month, day”.
Bài toán đơn giản như thế này có thể giải quyết với vài dòng code hoặc excel thông dụng. Nhưng vấn đề ở đây là tận 1TB dữ liệu, chúng ta không thể đọc toàn bộ lên với bộ nhớ máy tính đơn thuần. Đây là khi Spark phát huy tác dụng của nó.
Đối với yêu cầu này, Spark Driver sẽ nhận nhiệm vụ tiếp nhận job, điều phối các Executor đọc partition (một phần) data ví dụ 10 executors, mỗi executor sẽ đọc 100Gb chẳng hạn và xử lý tách ngày tháng năm. Kết quả cuối cùng sẽ được gửi về Driver để tổng hợp và xuất ra cho người dùng. Bởi vì cách thức hoạt động như vậy mà người ta gọi Spark là Distributed System (hệ thống phân tán).
Quay lại vấn đề lúc phỏng vấn, sau khi đã gãi đúng chỗ ngứa, tui thiết kế hệ thống ra sao?
Spark Cluster
Theo documentation, Spark có tổng cộng 4 cách để xây dựng hệ thống. Tuy nhiên để đáp ứng được yêu cầu của nhà tuyển dụng, tui chỉ có thể xem xét 2 phương án.
Spark on Yarn
Spark sẽ sử dụng hệ thống Yarn của Hadoop để quản lý tác vụ và cấp phát tài nguyên (CPU và RAM). Yarn là một framework hỗ trợ phát triển ứng dụng phân tán (resources manager), luôn luôn là một phần không thể thiếu của Hadoop. Đây cũng là cách xây dựng Spark phổ biến và được nhiều công ty sử dụng nhất. Về ưu điểm, thiết kế này sẽ không mất quá nhiều thời gian để phát triển khi có thể tái sử dụng hệ thống Hadoop có sẵn. Tuy nhiên sẽ có một số rắc rối đáng kể như sau:
- Vì tái sử dụng hệ thống, tui cũng chưa có thông tin số lượng users sẽ sử dụng Spark, liệu hệ thống cũ có đáp ứng nổi nhu cầu hay không. Còn nếu xây dựng một hệ thống Hadoop khác thì sẽ tốn thời gian phát triển và bảo trì cả 2 Hadoop.
- Hadoop sẽ scale dựa trên phần cứng, bằng cách gắn thêm server (node). Có thể coi là tốn kém cho công ty đang trên đà phát triển. Chưa kể đến trình tự rất phức tạp khi phải thông qua một số bước để cài đặt MapReduce Framework.
- Spark on Yarn không thể sử dụng khi công ty nâng cấp hệ thống lên Cloud.
Tuy nhiên nếu ai giải quyết vấn đề bằng cách này thì có thể coi là tạm chấp nhận vì đã giải quyết được 2/3 yêu cầu rồi.
Spark on Mesos
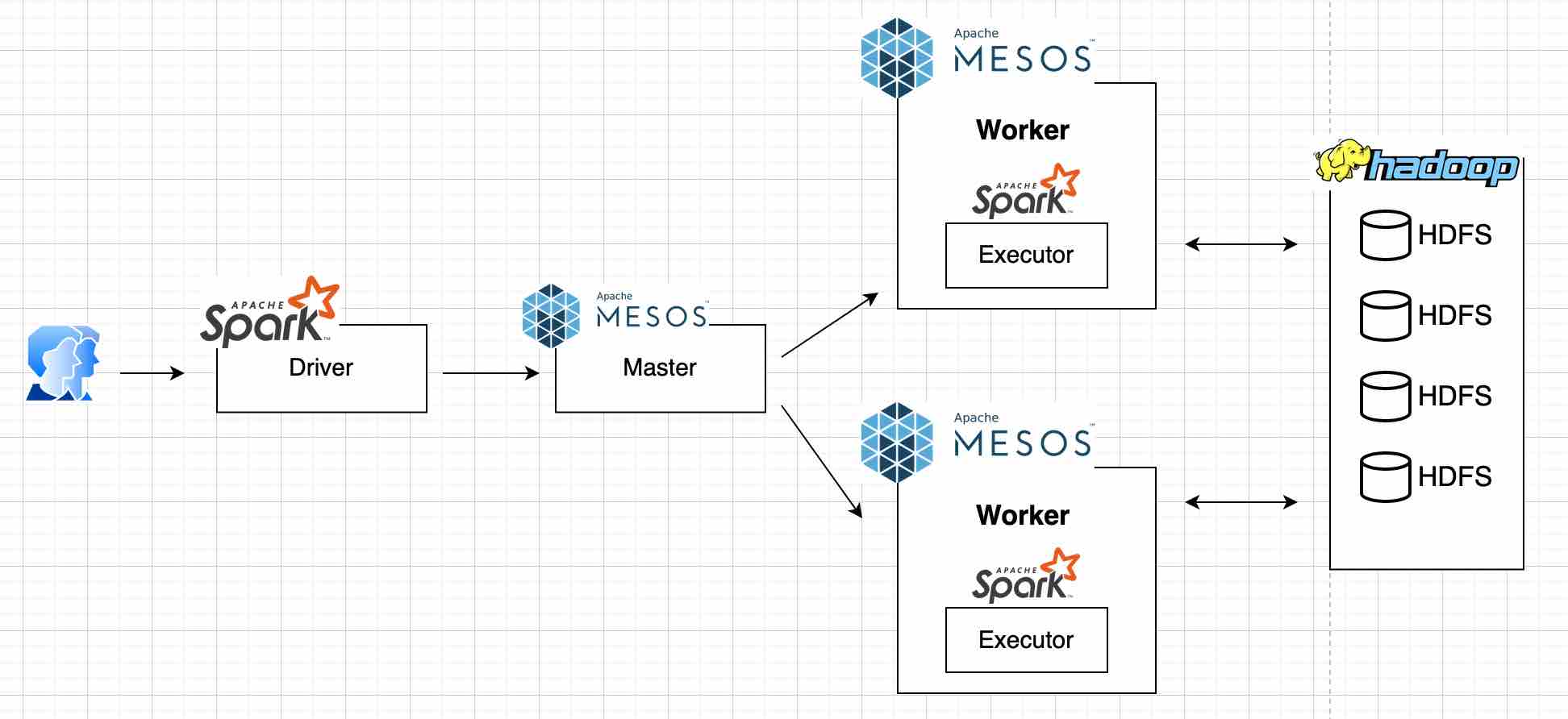
Tương tự như Yarn, Mesos cũng là một hệ thống quản lý phân tán. Tuy nhiên trong khi Yarn phải đi kèm với thuật toán Map Reduce của Hadoop thì Mesos lại có thể chạy độc lập.
Để dễ hình dung cho giới “phó thường dân”, tui lấy ví dụ về hình ảnh sân bay Tân Sơn Nhất, mỗi phút có rất nhiều máy bay yêu cầu cất cánh và hạ cánh, số lượng đường bay lại có hạn. Mesos chính là người điều phối việc cất cánh và hạ cánh của máy bay sao cho hiệu quả nhất với số lượng đường bay.
Áp dụng vào hệ thống của chúng ta, số lượng đường bay là số lượng máy (Workers) mà chúng ta có, yêu cầu cất cánh và hạ cánh chính là các Spark Jobs. Khi Spark Driver nhận yêu cầu xử lý 10 Jobs, Mesos sẽ điều phối các task vào những Workers trống mà nó quản lý, trường hợp nếu toàn bộ hệ thống đều bận, nó sẽ đưa Job vào Queue (hàng chờ) đến khi chạy được thì thôi.
Hệ thống Spark on Mesos hoàn toàn có thể giải quyết được bài toán trên:
- Mesos là một hệ thống riêng biệt, sẽ không đụng đến hệ thống Hadoop đã có sẵn của công ty.
- Việc scale Mesos hay thêm worker đơn giản hơn nhiều so với Hadoop. Mặc cũng liên quan đến phần cứng nhưng có thể đơn giản hóa bằng việc sử dụng Docker và Ansible.
- Như đã nói ở trên, Spark on Mesos có thể cài đặt bằng Docker nên tui có thể dễ dàng Migrate toàn bộ hệ thống lên Cloud trong tương lai.
Và cuối cùng sơ đồ hệ thống hoàn chỉnh như sau:
Qua bài viết này, tui hy vọng mọi người có một cái nhìn tổng thể về Spark. Đặc biệt là Spark trên production, và cách mà các công ty vận hành Spark. Lỡ ai đi phỏng vấn mà gặp câu hỏi tương tự cũng tự tin để chém gió với nhà tuyển dụng.
Anh chị em có ý kiến nào khác để giải bài toán trên vui lòng để lại comment, mọi người cùng thảo luận nha.
Credits: hình ảnh được lấy từ tui